

Posted on Apr 22, 2025 | AIML
Machine Learning Techniques
on this page
- Supervised Machine Learning
- Classification
- Regression
- Unsupervised Machine Learning
- Clustering
- Reinforcement Learning
- Anomaly Detection
- Dimensionality Reduction
- Ensemble Methods in Machine Learning
- Sequential Ensemble Methods (Boosting)
- Parallel Ensemble Methods (Bagging)
- Homogeneous vs. Heterogeneous Ensembles
- Common Ensemble Methods (Boosting, Bagging, Stacking)
Machine Learning Techniques in Python
Machine learning is a subset of artificial intelligence. Machine learning algorithms take a particular set of parameters as input and predict an output. A technique is a method of solving a specific problem. Let us look at the different machine learning techniques in Python.
Machine Learning Techniques
1. Supervised Machine Learning
Supervised learning is a type of machine learning that learns from labelled data. Labelled data is the type of data that has particular values assigned to it.
Supervised learning is used for structured datasets. It contains several data points or samples described with the help of an input variable (x). The output variable (y) is known as the label. The algorithm learns from the training dataset and creates a function that it will use on another input.
The algorithm needs to figure out the steps to go from input to output for any unknown data point given to it. We teach the algorithm with the help of a training dataset. If, at any point, the algorithm provides an incorrect output, we go back and train the model again by making slight adjustments.
An algorithm connects the input variable (x) to the output variable (y).
Categorization of Machine Learning Problems
There are three broad ways to categorize a machine learning problem:
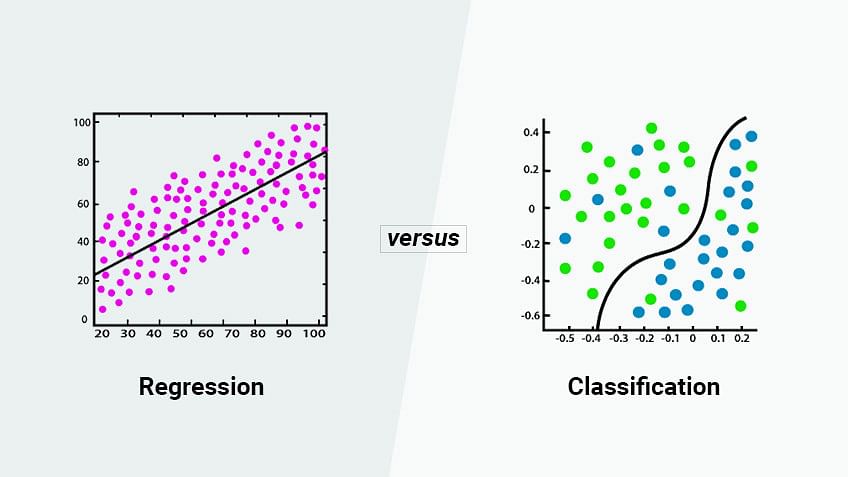
a. Classification
Suppose two people have decided to buy a product online.
- The experience of Customer A with the product was good.
- The experience of Customer B with the product was bad.
We need a model that distinguishes between good and bad experiences with a product for different customers. This is precisely what a classification model does.
Classification problems are further divided into:
- Binary Classification (e.g., good vs. bad)
- Multi-Class Classification (e.g., excellent, good, average, bad)
b. Regression
Regression problems are similar to classification problems, except the output is continuous real numbers rather than discrete labels.
2. Unsupervised Machine Learning
Unsupervised machine learning is used on raw datasets to find structures and patterns in unstructured data. It identifies existing patterns when no underlying truth is known to the model.
The most common unsupervised learning model is clustering, where natural clusters are grouped from an existing dataset. Although unsupervised learning is less commonly used than supervised learning, it plays a crucial role in data exploration.
The learning process in unsupervised learning is complex because the system lacks predefined input and output mappings. However, unsupervised learning has the power to uncover patterns within vast amounts of data.
a. Clustering
The clustering algorithm aims to detect common patterns and similarities between data points in the given dataset.
Examples of Clustering Applications
- Spam Filtering - Identifying and grouping spam messages.
- Book Recommendations - Suggesting books based on reading patterns.
The most common clustering algorithm is the K-means clustering algorithm.
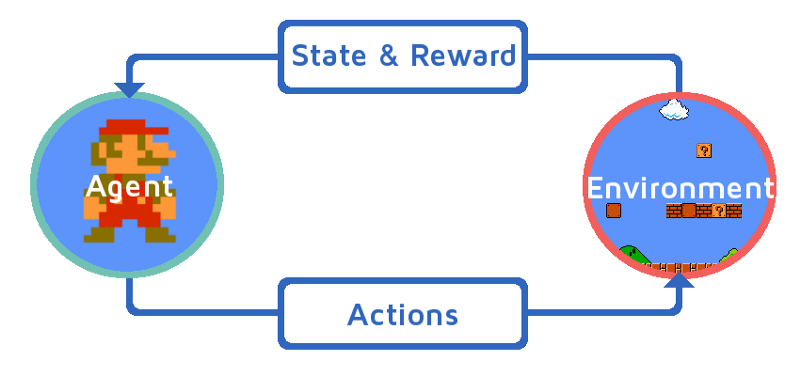
Reinforcement Learning
Reinforcement learning provides software with the freedom to decide the ideal behavior in any context. It enables an algorithm to maximize performance and grow over time. Feedback about a machine's performance helps it improve continuously.
In reinforcement learning:
- The agent decides the next step based on the current state.
- It allows machines to learn the outcome of their actions.
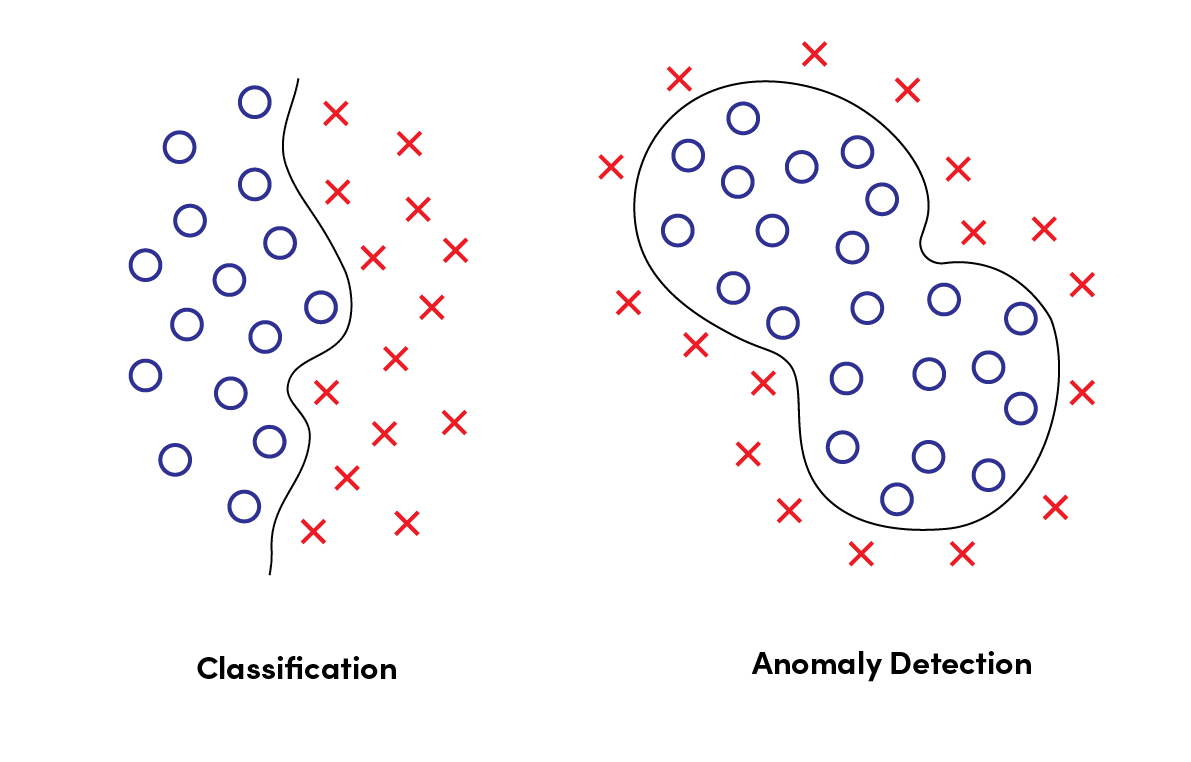
Anomaly Detection
Anomaly detection identifies unexpected events or patterns in a dataset. These anomalies differ from the regular flow of data.
Why Anomaly Detection?
- Recognizes abnormal activities that could impact the end-user.
- Prevents incorrect results by identifying faulty patterns.
- Ensures data integrity in large organizations.
Working Mechanism:
- The model is trained using data that contains faulty information.
- The machine learning model develops intelligence to detect faulty behavior.
- It analyzes recurring anomalies.
- These anomalies can then be corrected.
Dimensionality Reduction
Dimensionality reduction reduces high-dimensional data into a meaningful representation with fewer dimensions.
Why Dimensionality Reduction?
- Removes the curse of dimensionality.
- Ensures the projection of essential features.
- Helps in feature selection and feature extraction.
- Allows efficient predictions.
Concept:
- The minimum parameters required to describe the data are known as Intrinsic Dimensionality.
- N dimensions of a dataset can be reduced to k dimensions.
Ensemble Methods in Machine Learning
Ensemble methods combine multiple machine learning algorithms to form a meta-algorithm that enhances performance. This approach is used to:
- Decrease variance → Bagging
- Reduce bias → Boosting
- Improve predictions → Stacking
Instead of relying on a single decision tree, ensemble methods use multiple decision trees to improve predictive performance. The core idea behind ensemble methods is that many weak learners can collectively form a strong learner.
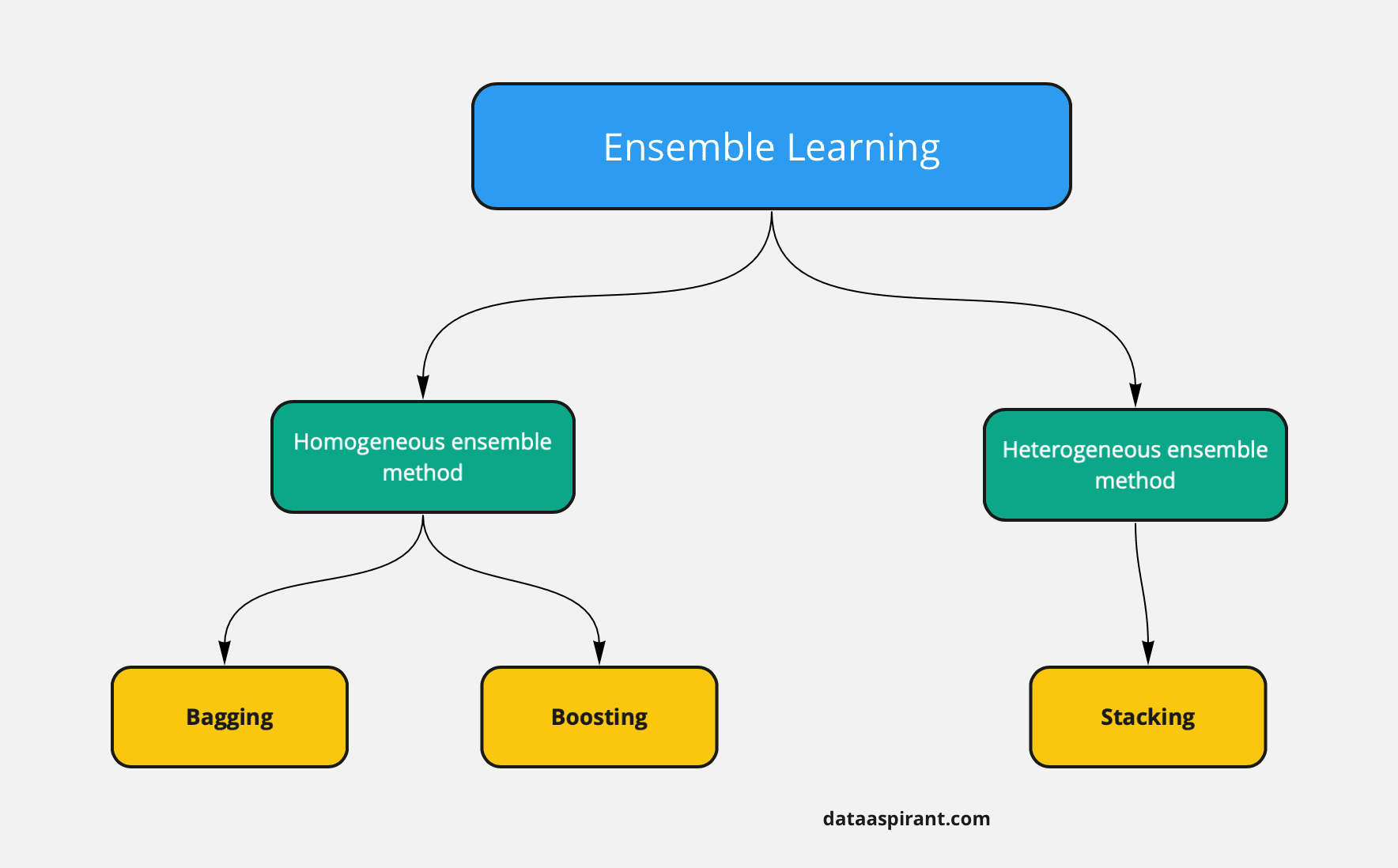
Types of Ensemble Methods
Ensemble methods are broadly classified into two categories:
1. Sequential Ensemble Methods
- Base learners are generated sequentially.
- Each model depends on the previous one.
- Example: Boosting, where weak models improve successively.
2. Parallel Ensemble Methods
- Base learners are generated in parallel.
- Models work independently to improve accuracy.
- Example: Bagging, where predictions are averaged.
Homogeneous vs. Heterogeneous Ensembles
- Homogeneous ensembles consist of similar types of learners forming a single base learning algorithm.
- Heterogeneous ensembles utilize different types of learners, leading to diverse ensemble structures.
Common Ensemble Methods
- Boosting - Combines weak learners by sequentially improving errors.
- Bagging - Aggregates multiple models to reduce variance.
- Stacking - Merges various models to create a meta-learner.
Ensemble methods play a crucial role in improving model accuracy and robustness. Let me know if you'd like any refinements!
Thanks for reading ~ Jai hanuman
1 Reactions
0 Bookmarks